~ 26 min read
Do not use secrets in environment variables and here's how to do it better

We developers are well too fond of using environment variables to set application configuration and often use it to store secrets and other sensitive information.
You already use an environment variable to set the port Nuxt runs on, or the BASE_API_URL for the Fastify Node.js web API you’re building, so why not use it to store the OPENAI_API_KEY or that serverless PostgreSQL DB_PASSWORD?
We all do it, right? Right.
Why do we do it though? why do we store secrets in environment variables?
Not because it’s secure. Not because it is a best practice. We store secrets in environment variables because it is easy. Because it is easy to put that API token in an environment variable. It’s easy to put the API token in Vercel’s deployment environment variables configuration. It’s easy to put the API token in a GitHub Action’s environment variables secrets configuration. It’s easy to put the API token in a .env file.
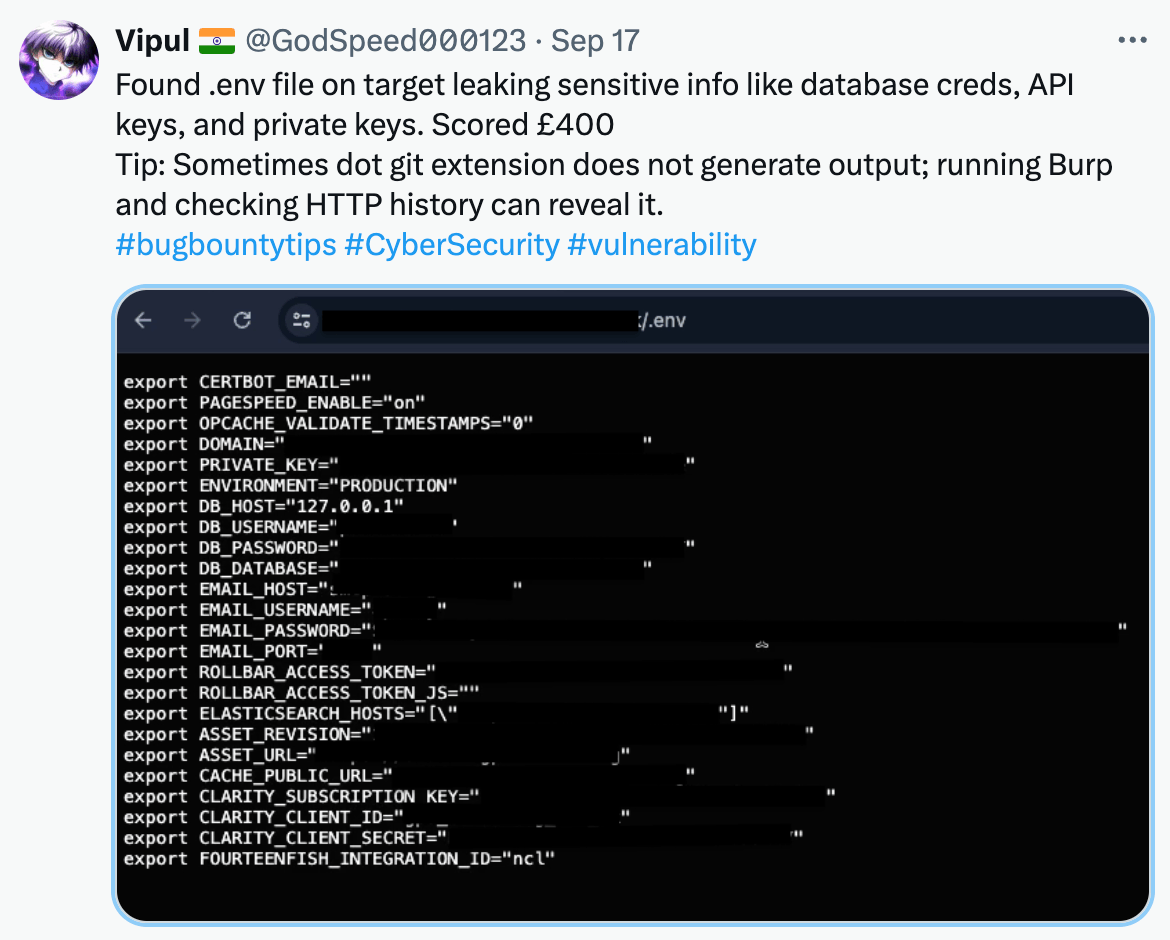
I mean, who hasn’t seen a .env file with a bunch of API_KEY=1234567890 or DB_PASSWORD=supersecretpassword ?
It’s easy. That’s why we do it. But we need to stop.
In this write-up:
- Is it wrong to store secrets in environment variables?
- Why you should not store secrets in environment variables
- ❌ Reason 1: Secrets in Environment Variables are Likely Poorly Managed
- ❌ Reason 2: The Blurry Line Between Frontend and Backend SSR Leaks Secrets
- ❌ Reason 3: Secrets in .env Files are Too Easy to Leak
- ❌ Reason 4: Secret Data Leaked by Logs
- ❌ Reason 5: Spawned Processes Share the Same Environment by Default
- ❌ Reason 6: Environment Variables are Visible in Process Lists
- ❌ Reason 7: Build Arguments and .env Files Leak into Docker Images
- 🙌 Proposal for Better Secrets Management
- FAQ
- But if I use a secrets management service I still have to pass clientSecret as environment variable?
- How does environment variables protect you against a malicious dependency?
- Doesn’t securely managing secrets offer some protection against a malicious dependency?
- How do I follow “secret zero” and provide a limited initial secret?
- Is this relevant if I’m running my Node.js application on Lambda?
Is it wrong to store secrets in environment variables?
If it’s a hobby project, or some application you’re toying with, or if it’s a non-critical application, not anything you’re deploying to production-like environment that has significant security risks and implications, then sure, go ahead, use environment variables to store your secrets if that’s an easy way for you to do it.
For anything else with a real consequence such as leaking user data, financial loss, or business risks, you should never store secrets in environment variables.
Why you should not store secrets in environment variables
In this section, I’ll list a handful of reasons and reference real-world incidents to help discourage why you should refrain from storing secrets in environment variables or any other kind of sensitive data.
❌ Reason 1: Secrets in Environment Variables are Likely Poorly Managed
To begin with, environment variables are not a secure way to store secrets, mostly and first-off, they are simply poorly managed, leading to a variety of security risks and compliance issues. Consider the following common pitfalls:
- Difficult to change when compromised: Imagine there’s now a data breach or one of your team members accidentally exposed an API token through a publishing a GitHub repository as public or in an npm package they pushed to the registry. Changing compromised secrets stored in environment variables often requires a full application restart or redeployment. Further, it requires accessing each and every provisioned instance to make the update. This process can lead to downtime, it’s very complex to roll-out in a distributed system, error-prone and requires a lot of coordination and communication from staff members. Let alone, how do you even know which services are using the compromised secret?
- Not rotated regularly: Environment variables are often set once for the infrastructure at play and forgotten, leading to static secrets that remain unchanged for extended periods. This is an anti-pattern when dealing with secrets and a bad practice overall since you may have pro-longed secrets that potentially got leaked in an incident that you may have not known about before. If you are familiar with JWT tokens and the need for short-time expiration then you can easily relate to this point and why regularly rotating your secrets is important. Implementing automated rotation for environment variables does require to use a more advanced mechanism for secrets like a secrets management service but that’s not something you trade-off in a production environment.
- Hard to audit: Environment variables lack built-in auditing capabilities. There’s no native way to track who accessed a secret, when it was last changed, or how it’s being used across the system. Even just figuring out where is said secret used across all of your deployed services, frontend, backend, SSR or otherwise. If you’re an enterprise or on a startup that seeks growth, this lack of visibility makes it difficult to comply with security standards like SOC 2 or HIPAA, which require detailed audit trails for access to sensitive information.
- Not encrypted at rest: Environment variables are typically stored in plain text on the host system. This poses a significant security risk for secrets because anyone with access to the host can potentially view these secrets. You did a feature demo of deploying the service and accidentally leaked the environment variables in a screen cast? You have a path traversal vulnerability? Those secrets are easily accessed through the
/proc/PID/environfile.
❌ Reason 2: The Blurry Line Between Frontend and Backend SSR Leaks Secrets
In particular with meta-frameworks such as Next.js, Nuxt and others, the lines between “client-side” and “server” has gotten very blurry. This is especially true with server-side rendering (SSR) and serverless functions, where the same codebase can run on both the client and the server.
With these frameworks, there’s no clear separation of frontend and backend code for developers in the form of a separate code repository for example. On the contrary, not only the codebase is shared but rather the framework itself is designed to act as either the frontend or the backend depending on the context.
Then, what happens when you adopt such server-side APIs with said frameworks and need to provision secrets via environment variables and framework-specific configuration? Mistakes. That’s what happens.
Here is the classic Vite example:
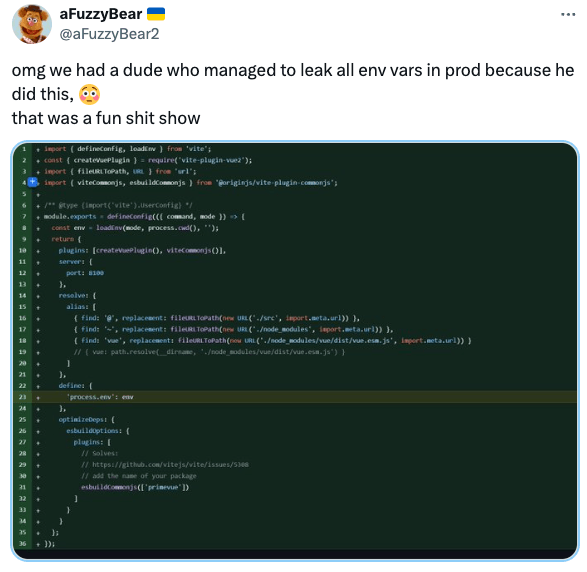
Next.js and Nuxt had have their fair share of similar confusing configuration. For example:
- In Next.js, you can differentiate between server-side vs client-side bundled environment variables by prefixing them with
NEXT_orNEXT_PUBLICrespectively. But what if you forget to prefix them correctly? What if you didn’t even realize that there’s a difference? (Here’s one reference, here’s another). - In Next.js, at one point in time at least, if you had added a
env: {}object in yournext.config.jsfile, it would expose all of the environment variables to the client-side bundle. This was a common mistake made by developers who were not aware of the implications of this configuration. (Here’s one reference)
This truly has severe and real-world implications. Don’t take it from me. Take it from this person who accidentally leaked their credentials in a Next.js application and suffered a crypto wallet compromise:
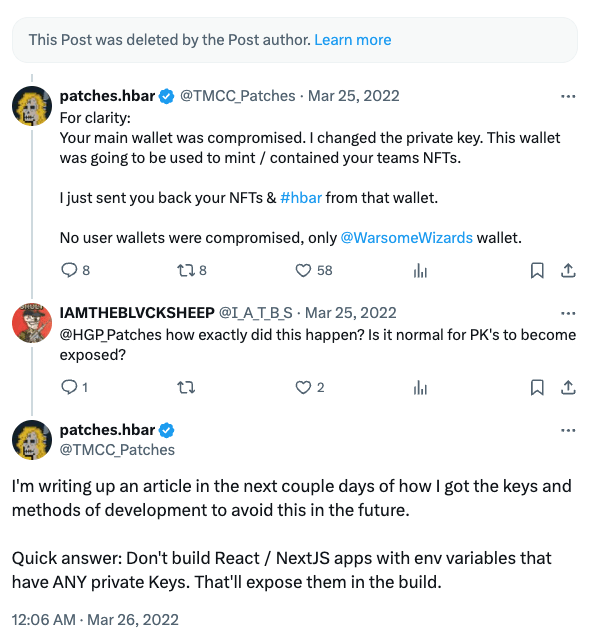
Both Next.js and Nuxt are doing their best to alleviate this issue by providing better documentation and creating more clear separation between client-side and server-side code. But the problem still persists and it’s up to you, the developer who employs this frameworks to be aware of the risks and take the necessary precautions.
❌ Reason 3: Secrets in .env Files are Too Easy to Leak
In continuation to this posts’ prelude - it is way too convenient to use a .env file to store configuration. As long as it is general configuration - while maintenance headache, at least not a security issue.
The moment you put secrets in a .env file, which is way too easy to do, you introduced two problems:
- You’ve violated the principle of separation of concerns. Application configuration and application secrets are two different things and should not be mixed together. Adding secrets to a
.envfile convolutes the two and makes it harder to manage and maintain. - You’ve introduced a security risk.
.envfiles end up committed to source control repositories, either accidentally or intentionally. This is a common mistake that can lead to secrets being exposed to unauthorized users.
How are your dev skills compared to developers at New England Biolabs? because they leaked their .env file with secrets to the public:
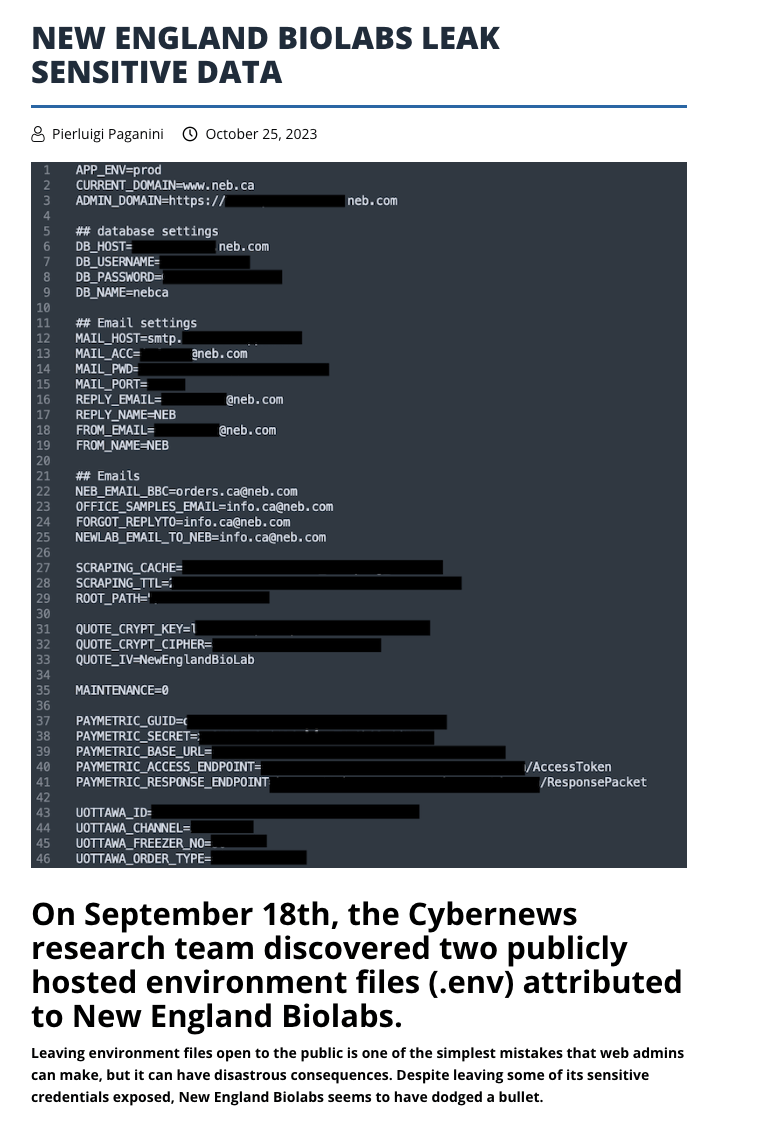
Or how about the time when developers leak secrets in environment variables when streaming?
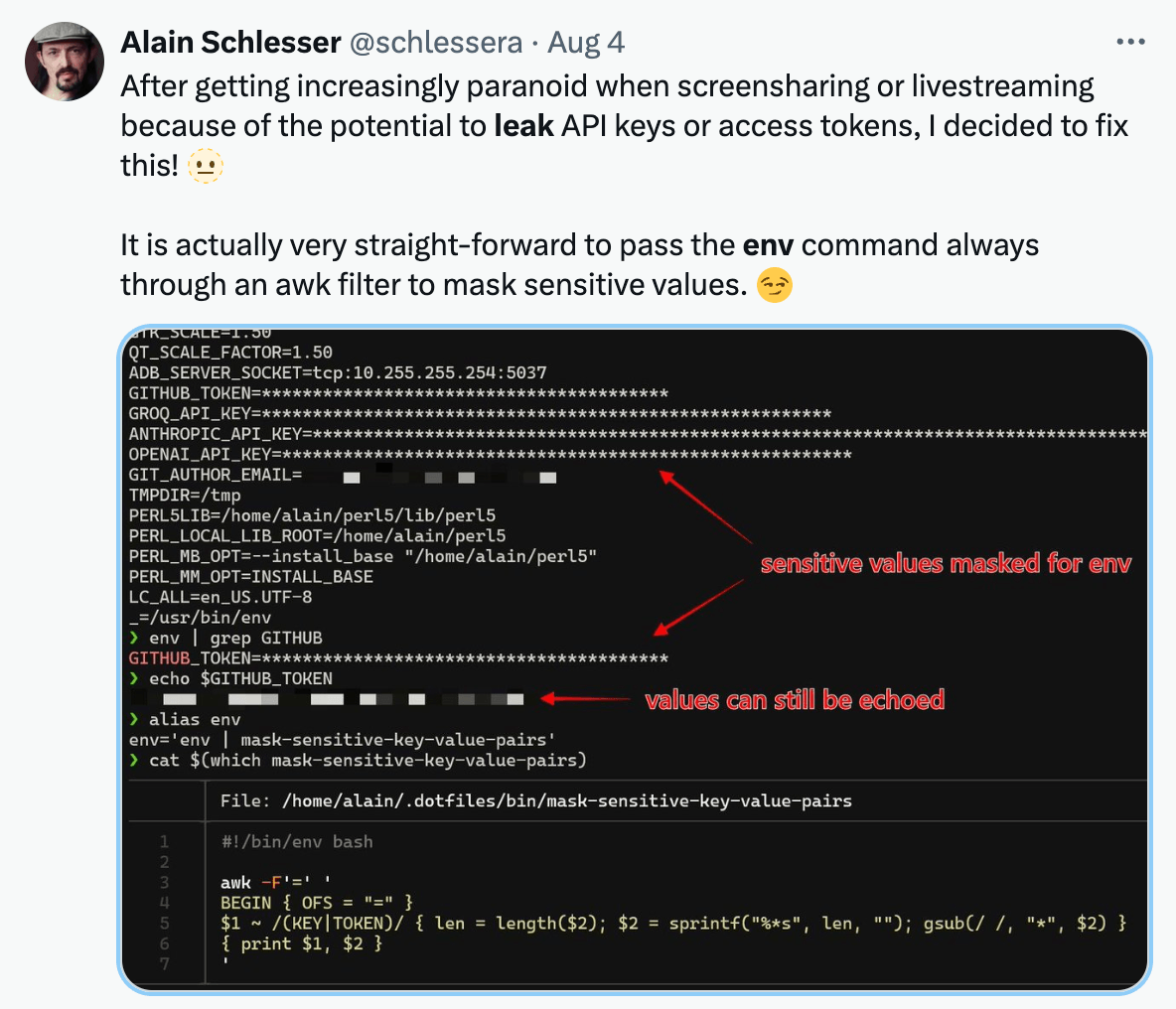
❌ Reason 4: Secret Data Leaked by Logs
Environment variables containing secrets are frequently exposed through logging mechanisms, often unintentionally. This data exposure can occur in unexpected error logs on the server, a rich debug output, or exception thrown crash reports, potentially revealing sensitive information to unauthorized users.
The risk here in particular is that secrets and credentials make it into logged data, whether on disk or in logging systems or services, which could then in turn be exposed through data breaches or unauthorized access. Practical example is a log entry with environment variables information pushed to a fire hydrant Slack channel and then accidentally shared with the wrong team members or exposed publicly.
The most ubiquitous example of this is the Express web application framework in Node.js. If you use Express, and you aren’t running the Node.js process with the explicit NODE_ENV=production environment variable setting, then the default behavior is that Express will produce verbose error messages in the response body, including the full stack trace.
Some other examples of how leaking secrets might come about are:
try { // Some operation} catch (error) { console.error('Error occurred:', error, 'Environment:', process.env);}Or how about:
if (process.env.DEBUG) { console.log('Debug info:', JSON.stringify(process.env, null, 2));}Or does this next one might look better?
process.on('uncaughtException', (error) => { const report = { error: error.stack, env: process.env, // Other debug info }; fs.writeFileSync('crash_report.json', JSON.stringify(report, null, 2));});All of these code examples seem so naive and rudimentary, huh?
Real-World Example: Seneca CVE-2019-5483
To serve as a practical reference for such security issues, I’ll refer you to CVE-2019-5483 - an information exposure vulnerability in the form of environment variables that leaked secrets, such as cloud API keys in one publicly referenced incident, that was found in the Node.js microservices toolkit called seneca.
Seneca was not as popular as Express but had a very decent user base with about 30,000 downloads a week.
Funny enough, the HackerOne bug bounty report involved Matteo Collina reporting this security vulnerability to the Node.js Security working group at that time (2019), in which I was a member of and helped coordinate the security disclosure
Here’s the patch that involved the fix:
diff --git a/lib/common.js b/lib/common.jsindex ef3e398..e992cd6 100644--- a/lib/common.js+++ b/lib/common.js@@ -339,10 +339,7 @@ exports.makedie = function(instance, ctxt) { process.arch + ', platform=' + process.platform +- (!full ? '' : ', path=' + process.execPath) +- ', argv=' +- Util.inspect(process.argv).replace(/\n/g, '') +- (!full ? '' : ', env=' + Util.inspect(process.env).replace(/\n/g, ''))+ (!full ? '' : ', path=' + process.execPath)
var when = new Date()❌ Reason 5: Spawned Processes Share the Same Environment by Default
When you use environment variables, the information stored in them is shared across all spawned processes. This comes with a particular risk when dealing with child processes.
In most programming languages, and true to Node.js, Bun, and Deno in particular for us JavaScript developers, the default behavior for spawned child processes is to inherit the environment variables data from their parent process. This means that any secret stored in an environment variable of the parent process becomes accessible to all of its child processes, regardless of whether they actually need that information.
Consider the following example in Node.js:
const { spawn } = require('child_process');const ls = spawn('my-program.js', ['/usr']);In this code snippet, the spawned process my-program.js will inherit all the environment variables from process.env of the parent process. This inheritance happens automatically, without any explicit permission or configuration.
When processes are spawned in this way, they are of clear violation of a fundamental security principle: the principle of least privilege. This principle states that every module or process should only have access to the information and resources that are strictly necessary for its legitimate purpose. When child processes automatically inherit all environment variables, they gain access to potentially sensitive information that they may not need. This unnecessary access increases the attack surface and the potential impact of a security breach.
This is also an opportunity to embrace a software architect mindset and think more broadly about the problem. Detach yourself from the concept of “web applications” and think about the impact of secrets in other settings, for example:
- An Electron based desktop application
- A CLI tool that you’re building
- A mobile application
Would you still store secrets in environment variables in these environments?
FAQ: But I don’t spawn child processes in my application
Maybe you don’t spawn child processes now, but you might in the future.
Maybe you don’t spawn child processes in your code, but a third-party library you use does.
Here’s an example of an npm package that converts images from one format to another and applies some image manipulation:
import {readFileSync} from 'fs';import {convert} from 'imagemagick-convert';
const imgBuffer = await convert({ srcData: readFileSync('./origin.jpg'), srcFormat: 'JPEG', width: 100, height: 100, resize: 'crop', format: 'PNG'});Under the hood? Here’s the lib/convert.js source code:
const {spawn} = require('child_process');
// ...// ...
/** * Proceed converting * @returns {Promise<Buffer>} */ proceed() { return new Promise((resolve, reject) => { const source = this.options.get('srcData');
if (source && (source instanceof Buffer)) { try { const origin = this.createOccurrence(this.options.get('srcFormat')), result = this.createOccurrence(this.options.get('format')), cmd = this.composeCommand(origin, result), cp = spawn('convert', cmd), store = [];
cp.stdout.on('data', (data) => store.push(Buffer.from(data))); cp.stdout.on('end', () => resolve(Buffer.concat(store)));
cp.stderr.on('data', (data) => reject(data.toString())); cp.stdin.end(source); } catch (e) { reject(e); } } else reject(new Error('imagemagick-convert: the field `srcData` is required and should have `Buffer` type')); }); }❌ Reason 6: Environment Variables are Visible in Process Lists
Environment variables are exposed in process lists. This exposure can lead to unintended disclosure of sensitive information to anyone with access to the system.
On most Unix-like operating systems (including Linux and macOS), it’s possible for any user on the system to view the environment variables of running processes. This means that secrets stored in environment variables are potentially visible to all users on the system, not just the owner of the process.
To illustrate this issue, let’s walk through a simple demonstration:
Open a terminal and run the following command:
$ SECRET_API_KEY=1234 node -e "console.log('hello world'); setTimeout(() => {}, 20000);"This command sets an environment variable SECRET_IN_ENV with the value admin and then runs the sleep command for 256 seconds.
Open another terminal window and run:
$ ps -wwwEOn macOS, this command lists all running processes along with their full environment variables. On Linux systems, you might use ps auxwe or ps eww for similar results. In the output, search for admin. You’ll find that the secret value is visible in plain text.
FAQ: But you can’t see processes of another user
Remember, we’re in the context of a web server or web application. We’re not talking about risks of multi-user systems where you have some sort of shared hosting where-in some user ssh’ed into the server and can see another user’s processes. No, I’m referring here to the web application itself getting exploited and such as, under whatever user it runs, it could expose environment variable data to the attacker. Let alone, there are likely many insecure and misconfigured container based deployments where the application runs as root anyway.
FAQ: But Gaining Access to the System is Unlikely
You might be raising the concern that gaining access to the system is unlikely and if a user has access to the system, they can already do a lot of damage.
I agree that the likelihood of an attacker exploiting this attack vector (viewing the process list) is relatively low. However, the potential impact of such an attack if it happens is high, especially in high-security environments. Some of the security risks would be around:
- Local User Access: Any user with access to the system can potentially view these secrets, even if they don’t have permission to access the application itself.
- Malware Risks: If the system is compromised by malware, even with limited privileges, it could potentially harvest secrets from the process list, simply by listing processes.
- Container Environments: In containerized environments, this issue can be even more problematic, as containers often run with elevated privileges on the host system.
With that said, please read in detail the next section on chaining vulnerabilities.
A Path Traversal Vulnerability Exposes Secrets in Environment Variables
In the information security and cybersecurity world, there’s the concept of layered security controls and the concept of defense in depth. This means that you should have multiple layers of security controls in place to protect your systems and data.
At the same time, attackers often chain multiple vulnerabilities together to exploit a system. This is known as a “vulnerability chain” or “attack chain”. One vulnerability might not be enough to compromise a system, but when combined with other vulnerabilities, it can lead to a successful attack and furthermore, to a vertical privilege escalation and lateral movement through a said system.
Here’s an example of how a path traversal vulnerability can be chained with the exposure of environment variables to leak sensitive information. Consider the following code snippet in Node.js that allows serving static file assets like CSS, JavaScript, SVG and others in the public/ directory:
const app = require('express')();
app.get('/public/*', (req, res) => { const filePath = path.join(__dirname, req.path.replace('/public/', '')); return res.sendFile(filePath);});This might not seem obvious to you but there’s a path traversal vulnerability in this code snippet.
I literally wrote over a hundred-pages long book particularly on the topic of Node.js Secure Coding and Path Traversal vulnerabilities made popular in Node.js applications and npm dependencies so you’d be shocked to know that this is a common mistake made by developers and maintainers alike.
👋 Just a quick break
I'm Liran Tal and I'm the author of the newest series of expert Node.js Secure Coding books. Check it out and level up your JavaScript


An attacker can craft a request to access any file on the server, including sensitive files like your package.json or config.json file, but I have a more interesting revelation for you.
Did you know that process information, including environment variables are available in the /proc filesystem on Linux systems? Ahh yes, definitely so! Here’s how you can access it:
$ cat /proc/12345/environ
# OutputSECRET_API_KEY=1234SHELL=/bin/bashNUGET_XMLDOC_MODE=skipCOLORTERM=truecolorCLOUDENV_ENVIRONMENT_ID=23232-33-33-bd9e-4424323232=/usr/local/share/nvm/versions/node/v20.16.0/include/node...Just replace the process ID 12345 with the one for the Node.js process running your application.
I hear you asking: “But how can you find the process ID of a Node.js process running on a server?”, and “how can you even access this file?”
Well, as simple as this cURL request available to anyone in the world:
$ curl http://your-website.com/public/../../../../proc/12345/environYou don’t need to know the process ID, you can just brute force it. This isn’t some UUID or GUID with billions of possibilities, it’s a simple integer that you can iterate over and in most cases this integer is going to end up in a low range.
Actually, wait. It’s even easier than that. You don’t even need to know the process ID AT ALL.
You can just access the /proc/self/environ file to get the environment variables of the current process. Here’s how you can do it:
$ curl http://your-website.com/public/../../../../proc/self/environAnd there you go, another reason why you shouldn’t store secrets in environment variables.
Note: the
/proc/self/environtrick only works when the server itself is exposed to local file inclusion or path traversal vulnerabilities
❌ Reason 7: Build Arguments and .env Files Leak into Docker Images
If you’re using Docker to containerize your applications you are likely making use of Docker build arguments. Docker build arguments, often used to pass secrets or sensitive information during image construction, can inadvertently leak into the final image, exposing confidential data.
Here’s the the problem at play - when using ARG instructions in a Dockerfile and passing secrets as build arguments, these values become part of the image’s metadata. It means that these secrets are visible in the image history and can be extracted by anyone with access to the image.
You typically might do something like this to pass a secret to a Docker build:
$ docker build . --build-arg MY_SECRET=1234 -t my-appThen, running the following Docker command will reveal the build argument MY_SECRET=1234 in the image history cache:
$ docker history my-appHow bad is this? According to studies, approximately 10% of images on Docker Hub are leaking sensitive data. This widespread issue highlights the importance of secure Docker image building practices.
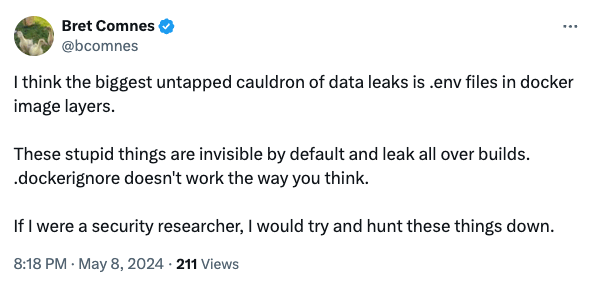
To make matters worse, Docker build arguments are just one vector for leaking secrets in Docker images. Other common vectors include storing the .env file in the built Docker image that also results in leaking credentials and secrets that are then kept in the image’s layers.
This is more common than you think, evidently, from Bret Comnes, a Senior Software Engineer at Socket.io:
There are however, more secure ways to build docker images, such as using multi-stage docker image.
🙌 Proposal for Better Secrets Management
To begin with, the hint lies in the title of this section: secrets management. Environment variables are hardly managed unless you explicitly use an integration or an orchestrator like Kubernetes to automatically inject environment variable configuration. For the vast majority of developers, environment variables are more of a “set and forget” practice.
I would like to propose a 3-fold principle to better secrets management:
- Always separate application configuration from secrets and credentials.
- Secrets are either completely injected to the application from an external resource as an ephemeral and short-lived access, or requested at runtime by the application. This breaks-down to several options:
- An infrastructure orchestration mechanism such as a Kubernetes sidecar container performs secure data fetching and make it available to the application by a temporary file available to the application to read during bootstrap, or a secret volume mount to the application container (popular with Docker Swarm and Kubernetes). Another option is a one-time, short-lived, secret (often known as token), provided through an environment variable.
- An external secrets management service is used to initiate a retrieval of secrets using temporary and short-lived token and the application is then responsible for fetching the secrets from the service as a follow-up runtime operation.
- Using the cloud vendor secrets management service to allow fetching secrets from application code and relying on authentication and authorization based on the cloud infrastructure and the application’s identity (IAM).
- Secrets are managed via a secrets management service or a key management service.
But how do you actually follow all of this in practice?
Well, secrets management solutions come in different shapes and sizes so I will refrain from recommending a specific one, but I don’t want to leave you hanging so let me provide a guideline on an adoption approach and how they differ. The following is listed in ascending order of complexity and security:
0. Solving the “Secret Zero” problem
Often times we have to face the “secret zero” problem. The “secret zero” problem is in essence the chicken and egg problem of having to provide a secret to access a secret.
This is why it is important to differentiate between storing secrets and providing secrets. If the application needs a single secret to bootstrap and then access a secret management service, you can provide the initial secret through an environment variable as long as the initial secret (often referred to as a token in many products, such as Hashicorp’s vault) is short-lived and has a limited usage count. This distinction is important because we treat the orchestration and the medium through-which the initial secret is provided as trusted sources, and once the application has bootstrapped and obtained the necessary secrets to function, the initial secret passed through the environment variable is discarded and expired. Even if leaked, it is useless.
Thus far, we described providing secrets to the application. If you however practice “secrets storage” which is storing long-lived secrets in environment variables, you’re opening yourself to the risks I outlined in this post.
1. The easiest and most convenient: secrets stores
A cloud service or a secrets store tool manage the secrets for you based on your .env file and they in turn integrate back with your application’s environment variables.
To call out a practical example: 1Password.
1Password is a password management service. Teams at companies use it to store and share passwords and other sensitive information through vaults. 1Password also has a CLI (called op) that reads your .env file and inject secrets to your application process.
Your .env file:
API_TOKEN="op://Onyx Team/Dev/OpenAI API Token/token"You then start the Node.js process as follows:
$ op run -- node app.jsWhen you run the 1Password CLI, it will authenticate you as it normally does (configure the fingerprint auth and you’ll enjoy a seamless experience), map the credential to the secret in the 1Password vault, and then inject the secret to the Node.js process environment. Your Node.js application can then use process.env.API_TOKEN to access it.
The down-side with this approach is:
- You’re still using environment variables, so some of the above mentioned security risks apply (secrets listed in logs, process lists, etc.)
- You probably don’t use 1Password in production, so you’re not getting the full benefit of a secrets management service. Although, 1Password does have a business offering that you can use in production.
Still, this is a better than nothing approach and a super convenient way to avoid exposing secrets in .env files.
2. The more secure and more complex: secrets management services
Offloading secrets entirely out of the environment variable scope.
In the previous approach with 1Password, you still needed to maintain and map each secret or credential to an environment variable name. That’s a manual process and completely exposes you to accidental leakage of all the secrets in the .env file.
A better way is to use a secrets management service, such as Infisical, HashiCorip Vault, or cloud vendor secrets management services like Google Cloud Secret Manager (which I feel comfortable calling out because I used it personally). These services either authenticate you based on the cloud infrastructure’s identity (i.e: IAM, and applies to the cloud vendor solutions) or via a temporary token (like Infisical) passed via environment variables (or an orchestrator).
To show a quick example of how you’d using Infisical (similar to how you’d use Google Cloud Secret Manager):
import { InfisicalSDK } from '@infisical/sdk'
const client = new InfisicalSDK();
await client.auth().universalAuth.login({ clientId: "<machine-identity-client-id>", clientSecret: "<machine-identity-client-secret>"});
const singleSecret = await client.secrets().getSecret({ environment: "dev", projectId: "<your-project-id>", secretName: "DATABASE_URL",});This is by far the preferred approach for anything you are building that is production-grade and has substantial and likelihood of a business impact.
FAQ
But if I use a secrets management service I still have to pass clientSecret as environment variable?
Yes, you do. But the difference with the clientSecret is vast compared to traditionally storing secrets in environment variables:
- This credential is only used to authenticate your application to the secrets management service. Once authenticated, the application service receives a temporary token that is used to fetch the secrets (you can think of it like doing JWT-based authentication workflow).
- Even if exposed or leaked, it is one secret to rotate rather than all of your secrets, scattered across all of your services and their environment variables.
- This secret can, and should, be configured with a short time-to-live (TTL) and maximum usage count. Meaning, it only serves a purpose for the initial grabbing of secrets when the application bootstraps and then it is useless.
- This secret is governed by a CIDR-based IP allow-list, so even if leaked in some way or stolen through a malicious dependency, it can only be used from a specific IP range (e.g: the office network, the cloud provider’s network, the company approved VPN, etc).
- This secret should be provisioned to application through secure trusted orchestration actor such as a Kubernetes sidecar, a CI/CD pipeline, or a cloud vendor’s secrets management service.
How does environment variables protect you against a malicious dependency?
If you have a malicious third-party dependency in your application then it effectively doesn’t matter how environment variables are managed or how you pass secrets because the malicious dependency has access to:
- Your file system and application environment (whether locally on your development machine or in the deployed production instance)
- Your code during runtime (execution)
Whether you store secrets in environment variables or if you use a secrets management service, the security of your application is effectively compromised and neither mechanism will protect you.
The problem here, really, lies with the fact that this question conflates two separate issues: the security of your application and the security of your secrets and there is no “silver bullet” answer to this question because we’re mixing two different things. With that said, if you just store your secrets in environment variables, a malicious dependency can easily access all of them, exfiltrate them to a remote server, and use them to compromise your application and infrastructure.
Doesn’t securely managing secrets offer some protection against a malicious dependency?
This question depends on the scope and context of the malicious dependency execution. If said malicious dependency is limited to executing during the build process, in which third-party dependencies are installed, and effectively allow install scripts to be run, and therefore execute arbitrary code, then securely managing secrets does offer some protection.
If you insecurely store your secrets in a .env file, environment variables or an arbitrary config.json file, then a malicious dependency can easily access these secrets and exfiltrate them to a remote server during the install / build process. Running npm install will allow any package in the dependency tree to execute arbitrary code, so it can just run env or cat .env and send the output to a remote server.
If however, you don’t actually store secrets as plain text on disk, and you don’t actually have any plain secrets in .env then a postinstall malicious dep hook would be useless in terms of exfiltrating secrets.
How do I follow “secret zero” and provide a limited initial secret?
Many secrets management services provide a way to authenticate and obtain a temporary, single-use token that can be used to further fetch secrets. This is often referred to as a “machine identity” or “machine identity client” and is used to authenticate the application to the secrets management service.
Some examples to call out for existing products:
- Hashicorp Vault, see their Secure introduction of Vault clients documentation.
- Infisical Token Auth, see their Token Auth authentication method documentation.
Is this relevant if I’m running my Node.js application on Lambda?
Serverless environments like AWS Lambda, or Vercel for that matter, are much more restricted and ephemeral which comes with some added benefits. However, some of the risks still apply, such as the security risk of exposing secrets in environment variables when the function crashes and the error message is logged or returned as an API response.
Another reason to consider moving away from environment variables for these serverless environments is that AWS Lambda, as one example, has a limited size for environment variables. If you have a large number of secrets or large secrets, you may run into issues with the size limit. For example: large JSON configuration payloads, large RSA keys, large JWT tokens, etc.
👋 Just a quick break
I'm Liran Tal and I'm the author of the newest series of expert Node.js Secure Coding books. Check it out and level up your JavaScript